Análisis de Documentos PDF con Langchain, OpenAI y Colab
Introducción
La extracción de información relevante de documentos PDF puede ser un desafío, especialmente cuando se trata de grandes volúmenes de texto. En este artículo, exploraremos un enfoque para abordar este problema utilizando herramientas como Langchain, OpenAI y Colab de Google. Además, se integrará un modelo pregunta-respuesta para obtener información específica de los documentos a través de Inteligencia Artificial.
Google Colab, también llamado Colaboratory ofrece un entorno de cuaderno basado en la nube que simplifica el desarrollo y la ejecución de código Python. Su utilidad se destaca en talleres y guías, ya que proporciona un entorno amigable y didáctico. Aquí, es posible integrar notas explicativas junto con bloques de código, permitiendo una ejecución paso a paso; de esta forma se simplifica revisar y probar el código ya que no será necesario configurar un ambiente en tu máquina.
LangChain es un marco para desarrollar aplicaciones basadas en modelos lingüísticos. Permite que las aplicaciones:
Sean conscientes del contexto: conecten un modelo lingüístico a fuentes de contexto (instrucciones, ejemplos de algunas tomas, contenido en el que basar su respuesta, etc.).
Razonen: se basen en un modelo de lenguaje para razonar (sobre cómo responder basándose en el contexto proporcionado, qué acciones tomar, etc.).
Los embeddings de OpenAI miden la relación entre cadenas de texto. Se utilizan habitualmente para:
Búsqueda (en la que los resultados se clasifican en función de la relevancia de la cadena de texto consultada).
Agrupación (las cadenas de texto se agrupan por similitud).
Recomendaciones (se recomiendan elementos con cadenas de texto relacionadas).
Detección de anomalías (identificación de valores atípicos poco relacionados).
Medición de la diversidad (análisis de las distribuciones de similitud).
Clasificación (las cadenas de texto se clasifican por su etiqueta más similar)
Alcance y Disclaimers
El alcance de este artículo se centra en el procesamiento de documentos PDF utilizando Langchain y OpenAI. Se abordarán los siguientes aspectos:
Extracción de Texto de PDF: Utilizaremos la biblioteca PyPDF2 para extraer el contenido textual de un documento PDF..
División de Texto: Se dividirá el texto en fragmentos más manejables utilizando la biblioteca langchain.
Generación de Embeddings: Se empleará OpenAIEmbeddings para convertir el texto en representaciones numéricas (embeddings).
Búsqueda de Similitud: Se utilizará FAISS para realizar una búsqueda de similitud en los embeddings generados.
Pregunta-Respuesta: Se implementará un modelo de pregunta-respuesta basado en OpenAI para obtener respuestas específicas del contenido de los documentos.
Es importante recalcar que el uso del API de OpenAI tiene costo, tal como se mencionó en el artículo
En este cuaderno se trata de explicar todo el código desarrollado y además se puede revisar paso a paso qué es lo que se está ejecutando, así como los outputs de las variables más importantes.
Para realizar la presente prueba se utilizó el libro El arte de la Guerra de Sun Tzu, libro de dominio público libre de derechos de autor que se puede descargar de
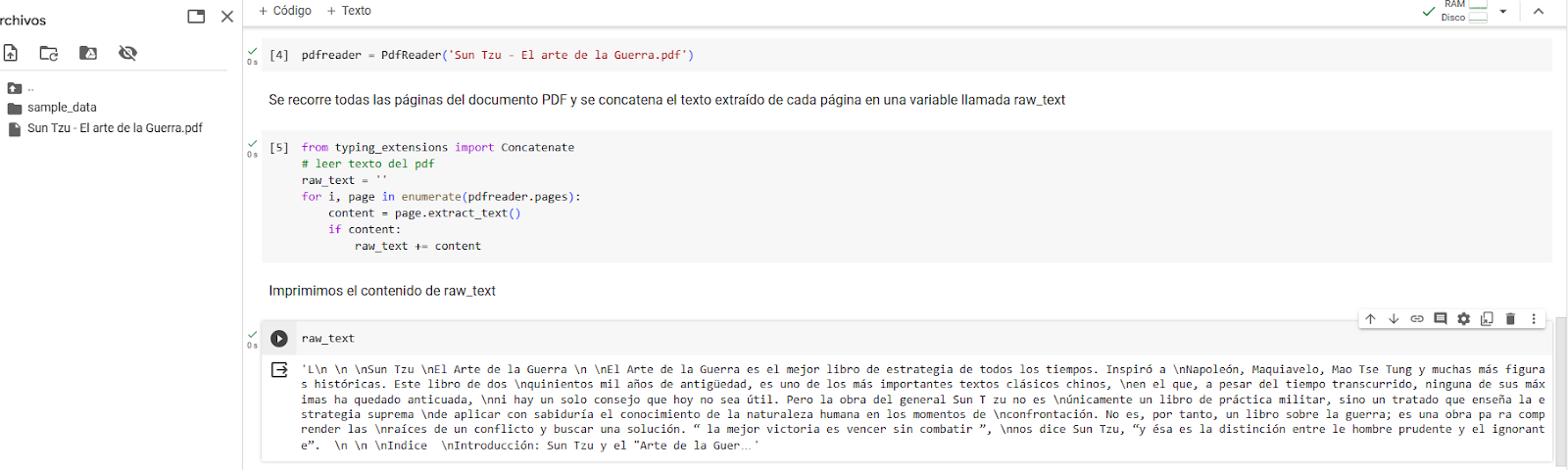
Una de las partes importantes dentro del taller es el contenido de la variable raw_text:
Como puede observarse en la imagen anterior dentro de raw_text se encuentra el texto del archivo pdf que enviamos a procesar.
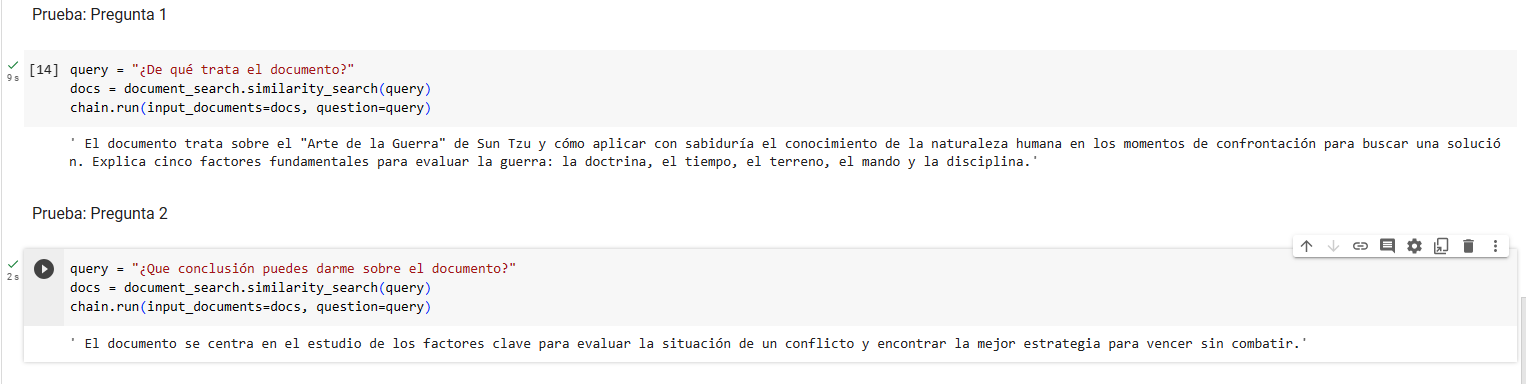
Luego de fragmentar el contenido de raw_text y crear la variable document_search podemos finalmente realizar las preguntas que necesitemos sobre el documento:
De nuevo, esta prueba la pueden realizar con cualquier documento pdf que deseen, simplemente subiendo el archivo y cambiando el nombre del mismo en el código tal como se explica en el cuaderno Google Colab.
Conclusiones
El uso de herramientas como Langchain y OpenAI Embeddings, facilita la extracción de información valiosa de documentos PDF. La combinación de técnicas como la división de texto, la generación de embeddings y la búsqueda de similitud permite un análisis más profundo de grandes conjuntos de datos textuales.
La integración de modelos de pregunta-respuesta basados en inteligencia artificial, como el proporcionado por OpenAI, amplía aún más las capacidades de este enfoque, permitiendo a los usuarios realizar consultas específicas y obtener respuestas relevantes.
En resumen, este artículo destaca un enfoque práctico para el procesamiento de documentos PDF y la extracción de información utilizando herramientas populares de procesamiento de lenguaje natural y aprendizaje automático, todo implementado en el entorno colaborativo de Google Colab.



skapa binance-konto
Your article helped me a lot, is there any more related content? Thanks!