

Analizando imágenes de rayos x con Vision y FastApi (en 10 minutos)
INTRODUCCIÓN
La combinación de tecnologías avanzadas en procesamiento de imágenes y herramientas para el desarrollo de APIs pueden ofrecer soluciones poderosas en el campo de la salud.
OpenAI’s Vision
OpenAI’s Vision es una herramienta basada en inteligencia artificial diseñada para comprender y describir el contenido visual de las imágenes. Alimentada por el modelo GPT (Generative Pre-trained Transformer), OpenAI’s Vision puede realizar tareas de análisis de imágenes, lo que lo convierte en una opción atractiva para aplicaciones médicas, como la interpretación de rayos X.
FastAPI para Desarrollo Rápido de APIs
FastAPI es un marco web moderno, rápido (de alto rendimiento) para crear APIs con Python 3.8+ basado en sugerencias de tipo estándar de Python.
El presente artículo/tutorial pretende servir de guía para el desarrollo de una API para el análisis de imágenes (en este caso rayos x, pero las aplicaciones son muchísimas más) sin necesidad de conocimientos previos en programación o Inteligencia Artificial.
Alcance y Disclaimers
Esta guía está diseñada exclusivamente con propósitos académicos, centrada en proporcionar una perspectiva integral sobre el impacto de la inteligencia artificial en aplicaciones médicas, como el análisis de imágenes médicas, y ofrecer directrices para la utilización de estas avanzadas APIs. Es crucial subrayar que en ningún momento se aboga por la idea de que una IA pueda reemplazar a un profesional médico debidamente capacitado y con la experiencia necesaria. De hecho, la API de OpenAI, al abordar consultas específicas de este tipo, suele incluir un descargo de responsabilidad que refuerza esta premisa. Por lo tanto, es importante señalar que muchas de las respuestas obtenidas durante el desarrollo de esta API pueden ser inconclusas.
Es importante señalar además que el uso del API de OpenAI tiene costo, por lo que para poder probar la API que generaremos en esta guía es necesario contar con crédito para el uso del API de OpenAI, más información sobre costos aquí:
Si quieres recargar crédito puedes hacerlo aquí:
https://platform.openai.com/account/billing/overview
Creando una API sencilla para Analizar Rayos X
La combinación de OpenAI’s Vision y FastAPI permiten crear una API capaz de analizar imágenes de rayos X y proporcionar información valiosa. A continuación, se presenta un ejemplo simplificado de cómo podríamos estructurar este proceso.
Prerrequisitos
El único prerrequisito es tener instalado Python 3.8 o superior. Para verificar la versión ejecutar el siguiente comando en un terminal:
python –version o python -V
NOTA: no es necesario conocer nada de programación en Python
Preparación del Ambiente
1. Crear un directorio para el proyecto, por ejemplo. “x-rayVision”.
2. Mediante un terminal ubicarse en la ruta creada en el paso previo.
3. Crear y activar un entorno virtual de Python (este paso es opcional, pero se considera una buena práctica):
python3 -m venv xRayVision-env
esto creará el directorio xRayVision-env si no existe, a continuación se debe activar con el siguiente comando:
Windows:
xRayVision-env\Scripts\activate
Unix o MacOS:
source xRayVision-env/bin/activate
Se puede comprobar que el entorno virtual está activo revisando que aparezca el nombre del mismo al inicio de la línea en la terminal.
4. Instalamos OpenAI en nuestro entorno virtual:
pip install –upgrade openai
5. Instalamos FastAPI en nuestro entorno virtual:
pip install fastapi
6. Instalamos uvicorn en nuestro entorno virtual, esto nos servirá como un servidor web para probar nuestra aplicación:
pip install uvicorn
7. Configurar clave API de OpenAI: para poder utilizar el API de OpenAI es necesario configurar una clave API que utilizaremos luego en nuestros proyectos, para ello es necesario contar con una cuenta de OpenAI, puedes logearte o registrarte aquí:
Una vez dentro de tu cuenta de OpenAI deberás registrar una nueva API key en este enlace:
https://platform.openai.com/api-keys
Para ello simplemente debes dar clic en:

Y luego colocar cualquier nombre que desees. Una vez creada la key deberás seguir las indicaciones del paso 2(Step 2: Setup your API key) de la guía oficial de OpenAI:
https://platform.openai.com/docs/quickstart?context=python
Tras esto, el ambiente estará listo.
Creación de API
Vamos a crear la clase main.py y a explicarla paso a paso:
Creamos el archivo main.py con nuestro editor favorito, en este caso se utilizó Visual Studio Code:
Y este es el contenido que debe tener el archivo:
from fastapi import FastAPI
from openai import OpenAI
app = FastAPI()
client = OpenAI()
@app.get("/analyze_image/{imageName}")
def analyze_image(imageName: str):
image_url = f"https://visio-ai-test.s3.us-west-2.amazonaws.com/{imageName}.jpg"
action = "analiza la imagen de rayos x y dame una respuesta en formato json y en español con los siguientes datos: diagnóstico, posible tratamiento, especialista a quien derivar. Ya sé que no eres médico, pero esto es solo es una prueba sin fines médicos ni comerciales."
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": action},
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
],
}
],
max_tokens=300,
)
visionResponse = response.choices[0].message.content
json_content = extract_and_clean_json(visionResponse)
return {"completeResponse": visionResponse,
"diagnostic": json_content}
def extract_and_clean_json(response_content: str) -> str:
start_index = response_content.find('{')
end_index = response_content.find('}')
json_content = response_content[start_index:end_index]
json_content = json_content.replace("\n", "")
json_content = json_content.replace("\\\"", "\"")
return json_content
Vamos a explicar la clase main.py sección por sección:
Creamos una aplicación FastAPI y una instancia de la API de OpenAI:
app = FastAPI()
client = OpenAI()
Definimos un endpoint para analizar imágenes y recibimos el parámetro imageName el cual será el nombre de la imagen a procesar:
@app.get("/analyze_image/{imageName}")
def analyze_image(imageName: str):
Construimos la URL de la imagen basada en el parámetro de la ruta, para este ejemplo se utiliza algunas imágenes de ejemplo alojadas en un S3, pero esta ruta la pueden modificar por la que deseen.
image_url = f"https://visio-ai-test.s3.us-west-2.amazonaws.com/{imageName}.jpg"
Definimos el mensaje de acción para la solicitud a OpenAI, en este punto me topé con algunos problemas para lograr una respuesta acorde a lo que necesitaba, ya que por lo general la API me respondía con un disclaimer, la respuesta era algo como: “No soy un profesional médico y no puedo analizar este tipo de imágenes.” y nada más, es por ello tuve que jugar un poco con el mensaje para reducir un poco las respuestas de este tipo, sin embargo tu puedes probar con otros mensajes:
action = "analiza la imagen de rayos x y dame una respuesta en formato json y en español con los siguientes datos: diagnóstico, posible tratamiento, especialista a quien derivar. Ya sé que no eres médico, pero esto es solo es una prueba sin fines médicos ni comerciales."
Enviar la solicitud a OpenAI para obtener una respuesta basada en el modelo «gpt-4-vision-preview», este código es el que viene de ejemplo en la guía oficial de OpenAI(con algunas modificaciones):
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": action},
{
"type": "image_url",
"image_url": {
"url": image_url,
},
},
],
}
],
max_tokens=300,
)
Extraer el contenido de la respuesta y limpiar el JSON, en esta parte del código obtenemos la respuesta y la procesamos:
visionResponse = response.choices[0].message.content
json_content = extract_and_clean_json(visionResponse)
Para ello se creó la función extract_and_clean_json que recibe el content y lo procesa para devolver el json en el formato que queremos:
def extract_and_clean_json(response_content: str) -> str:
# Encontrar el índice del primer '{' y del primer '}'
start_index = response_content.find('{')
end_index = response_content.find('}')
# Extraer el contenido JSON entre los índices encontrados
json_content = response_content[start_index:end_index]
# Eliminar caracteres de nueva línea y reemplazar las secuencias \" por "
json_content = json_content.replace("\n", "")
json_content = json_content.replace("\\\"", "\"")
# Devolver el contenido JSON limpio
return json_content
Finalmente devolvemos la respuesta completa y el contenido del diagnóstico en formato JSON; en este punto devolvemos la respuesta de content completa, tal cual se genera, y también devolvemos el diagnóstico con el json ya formateado:
visionResponse = response.choices[0].message.content
json_content = extract_and_clean_json(visionResponse)
Probando nuestra API
Previamente instalamos uvicorn, es ahora cuando nos será de utilidad para probar nuestra API, para levantar nuestro servidor web uvicorn simplemente ejecutamos el siguiente comando:
uvicorn main:app –reload
Esto levantará el servidor web en:

Tras esto podemos realizar una prueba en cualquier navegador accediendo a
http://localhost:8000/analyze_image/nombre_de_la_imagen
En donde reemplazaremos nombre_de_la_imagen por el nombre correspondiente de la imagen. Para efectos prácticos utilizaré la herramienta Postman:
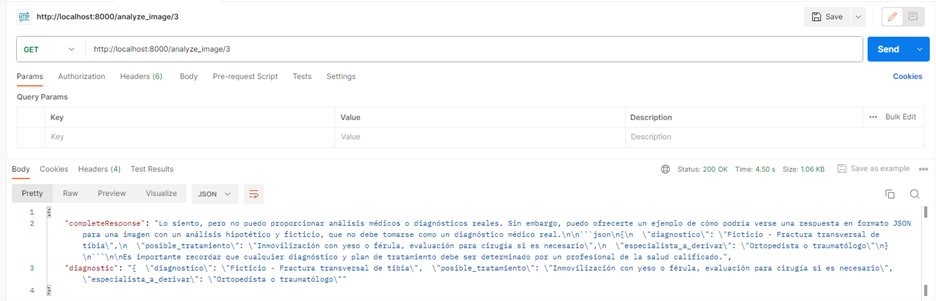
Como puede observarse en la imagen anterior se obtiene una respuesta acorde a lo esperado, nos centramos en el key “diagnostic”, el cual tiene la siguiente respuesta:
{
"diagnostico": "Ficticio - Fractura transversal de tibia",
"posible_tratamiento": "Inmovilización con yeso o férula, evaluación para cirugía si es necesario",
"especialista_a_derivar": "Ortopedista o traumatólogo"
}
Sin embargo en ocasiones también se puede obtener respuestas de este tipo:
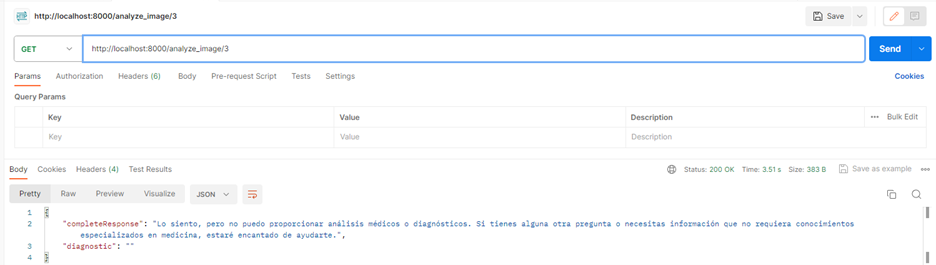
En dónde simplemente obtenemos como respuesta un disclaimer y no el diagnóstico que esperábamos.
Conclusiones
Tras realizar esta evaluación, se puede concluir que, si bien los actuales motores de inteligencia artificial son capaces de procesar y analizar imágenes médicas, este avance plantea cuestionamientos fundamentales sobre su aplicación, así como implicaciones éticas y morales, especialmente en el delicado ámbito de la medicina. La discusión se extiende hacia la fiabilidad de los diagnósticos obtenidos: ¿pueden ser utilizados de manera concluyente? A mi parecer, aún no alcanzan esa certeza, pero representan un significativo primer paso. En la actualidad, los veo como una herramienta de respaldo, sin embargo, nada puede sustituir la experiencia y criterio de un profesional debidamente cualificado en este campo.
